
.svg)
.svg)


Build. Train. Optimize.
AI for the edge.
Build datasets, train models, and optimize libraries to run on any edge device, from extremely low-power MCUs to efficient Linux CPU targets and GPUs.










Any data, any device
Edge Impulse developers can get data from various sources, including their own sensor hardware, public datasets, and data generated through simulations or synthetic data generation.
Unlock sensor data value
Build high-quality sensor datasets and leverage advanced data analysis tools to quickly detect data quality issues with any dataset.
Advance algorithm development
Shorten your product development lifecycle by leveraging device-aware feature engineering tools and enterprise-ready AI architectures to develop algorithms optimized for health and industrial use cases.
Optimize edge AI models
Optimize any model by profiling its on-device performance and tuning it to leverage your specific hardware acceleration capabilities.
Target agnostic edge deployment
Future-proof your workflow by allowing you to generate models and algorithms that will perform at peak efficiency on any edge hardware.

.webp)
.webp)

.webp)
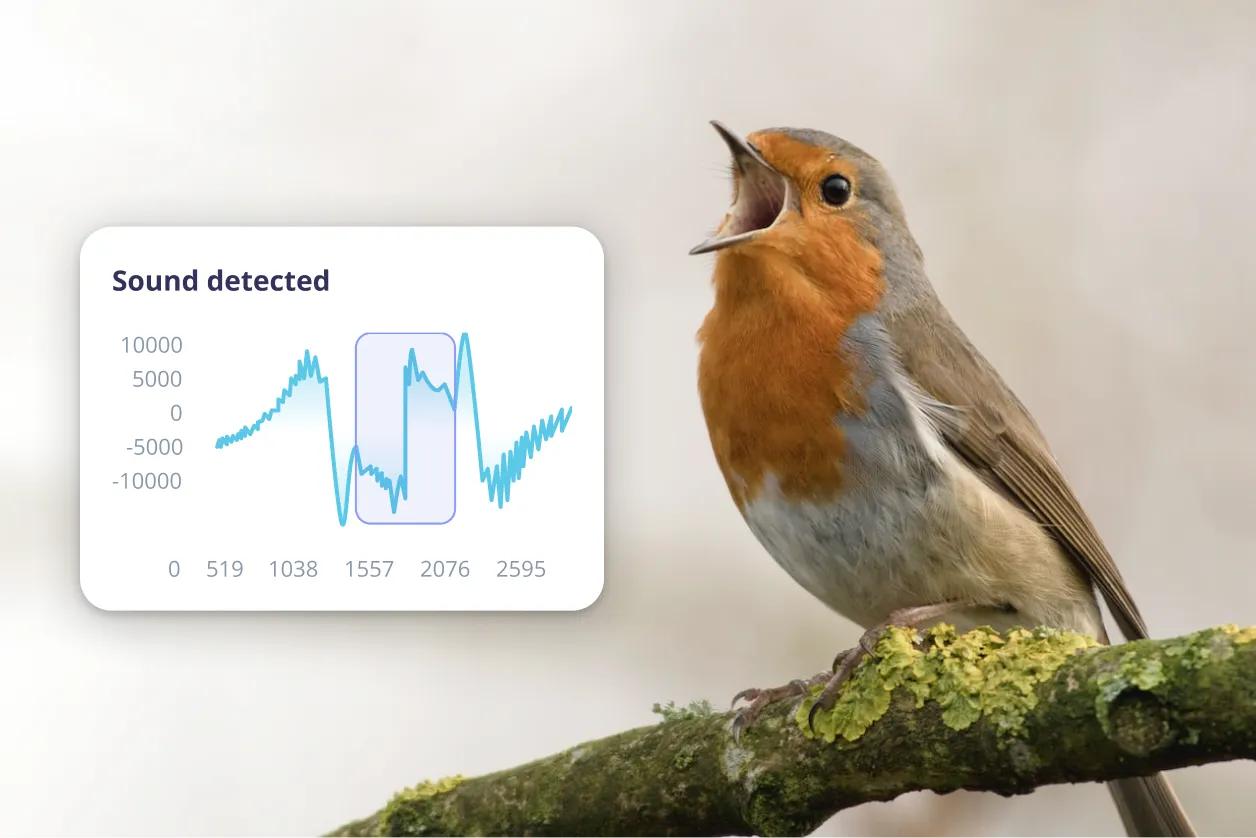
Easily integrate with existing ML workflows
Collaborate across your data, ML, and embedded teams to build optimized production-ready models faster.

Achieve measurable results
Future-proof your products. Our customers win by adding edge intelligence to their products, from low-power wearables to industrial gateways.


.svg)

.svg)
.webp)

.svg)
Edge AI for professionals
Product Leaders
Discover why product managers choose Edge Impulse to accelerate AI-powered solutions.
AI Practitioners
Leading AI professionals tap into Edge Impulse to deploy any ML model across every edge device.
Embedded engineers
Nearly 100,000 engineers pick Edge Impulse as their ML platform of choice.
Build with the world’s top hardware, sensors, and cloud platforms
Benefit from built-in integrations with our leading partner ecosystem including MCUs to MPUs and GPUs, sensors, cloud services, data science tools, and digital twin platforms.

Get started with
Edge Impulse



